tl;dr: Ensure your requests are eligible for caching (even if responses aren’t) so that they use Tiered Cache’s faster architecture. For example, you can create a Cache Rule with the Use cache-control header if present, bypass cache if not action for Edge TTL.
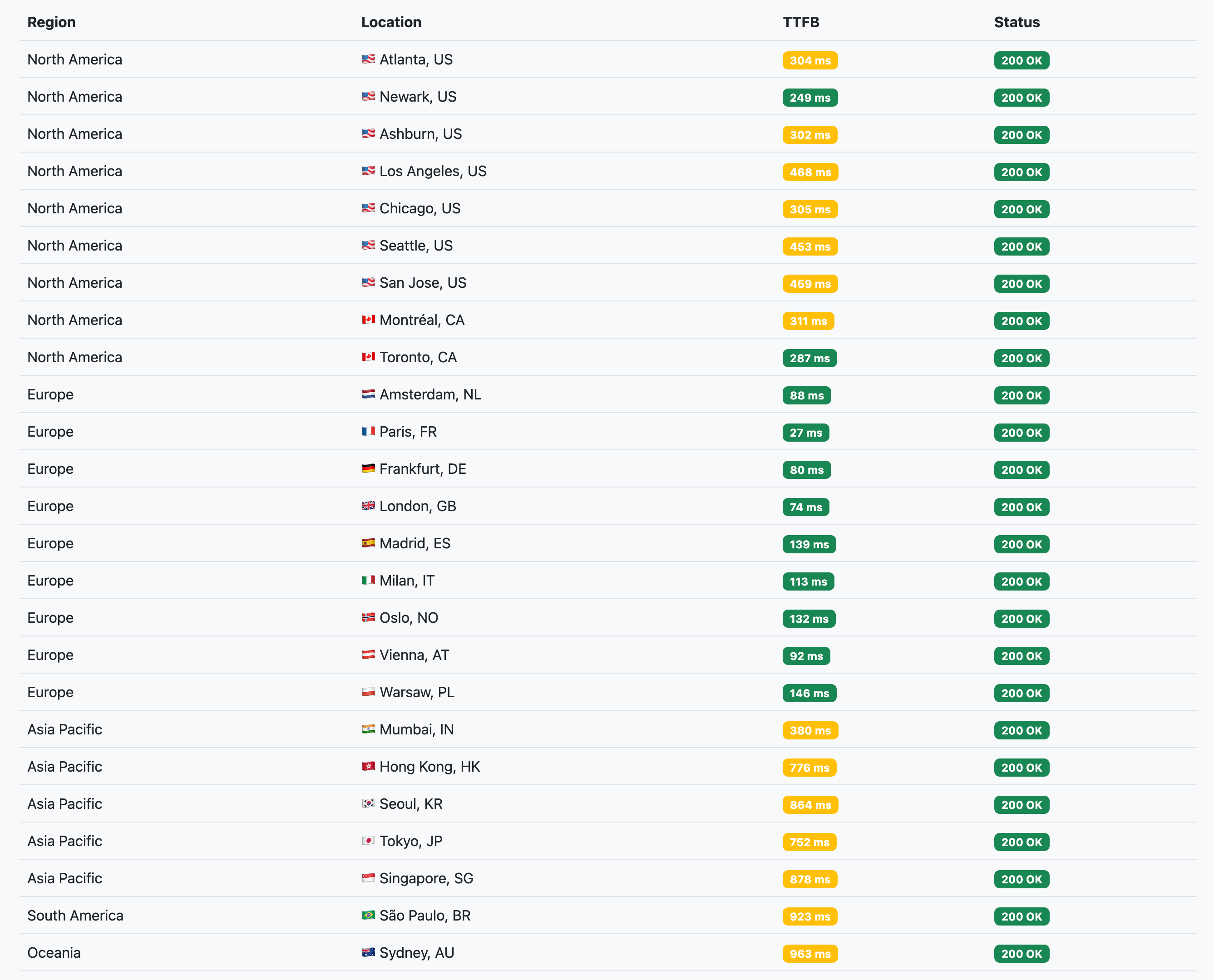
Checking on a webapp’s performance, I found latency results from farther away countries underwhelming. This app runs on AWS in eu-west-3 (Paris), with Cloudflare in front for DDoS protection and caching of static assets.
The configuration was close to the defaults, and Tiered Cache was enabled (set to Smart Tiered Caching Topology).
An aside on Cloudflare’s Tiered Cache
Well, Tiered Cache is pretty amazing, and free. According to Cloudflare:
By enabling Tiered Cache, Cloudflare will dynamically find the single best upper tier for an origin using Argo performance and routing data.
This practice improves bandwidth efficiency by limiting the number of data centers that can ask the origin for content, reduces origin load, and makes websites more cost-effective to operate.
Also, and this is of importance, Cloudflare carries requests and responses very efficiently between the client data center and the upper tier, which in turn communicates with the origin on cache misses. In fact, way more efficiently than if the client data center stretched a TCP session all around the world to speak directly to the origin. This makes the request-response round trip far faster, even for non-cacheable content, as things like TLS handshakes are way quicker on short distances.
Reading this, we’d think that it applies to all requests. Well, we’d be wrong.
The problem
Cloudflare’s request processing logic is made of multiple phases each responsible for a specific product like WAF, Rate Limiting or Cache. As I understand it, at or before the beginning of the Cache phase, Cache Rules and the default policy1 are used to determine whether the request looks like it is for cacheable content. If not, caching is bypassed entirely. This is what happens when you see DYNAMIC in the CF-Cache-Status response header. In theory, that’s good because it prevents expensive-ish cache lookups and useless processing for requests that have no hope to ever be cached anyway.
However, as Tiered Cache is part of the Cache phase, it doesn’t get to engage for those ineligible requests. Origin requests then come from the Cloudflare data center that received the client request rather than Tiered Cache’s upper tier data center. This is suboptimal:
- As both Cloudflare and many hosting providers are doing hot potato routing, packets travel freely over the Internet through paths that no one really monitors nor optimizes for performance2, leading to high latency.
- The client data center might be very far away from the origin, making even the most direct non-congested path tens to hundreds of milliseconds long, which TCP doesn’t like very much.
Cache Rules to the rescue
Even if we know our content is not cacheable and never will be, we want the client data center to think there’s still a chance so that the Cache phase isn’t skipped and all3 traffic goes through Tiered Cache, cold potato-style4, only exiting to the origin from the upper tier data center.
To do that without altering the existing behavior, we created a Cache Rule targeting only requests not covered by the default policy and applied the Use cache-control header if present, bypass cache if not action for Edge TTL.
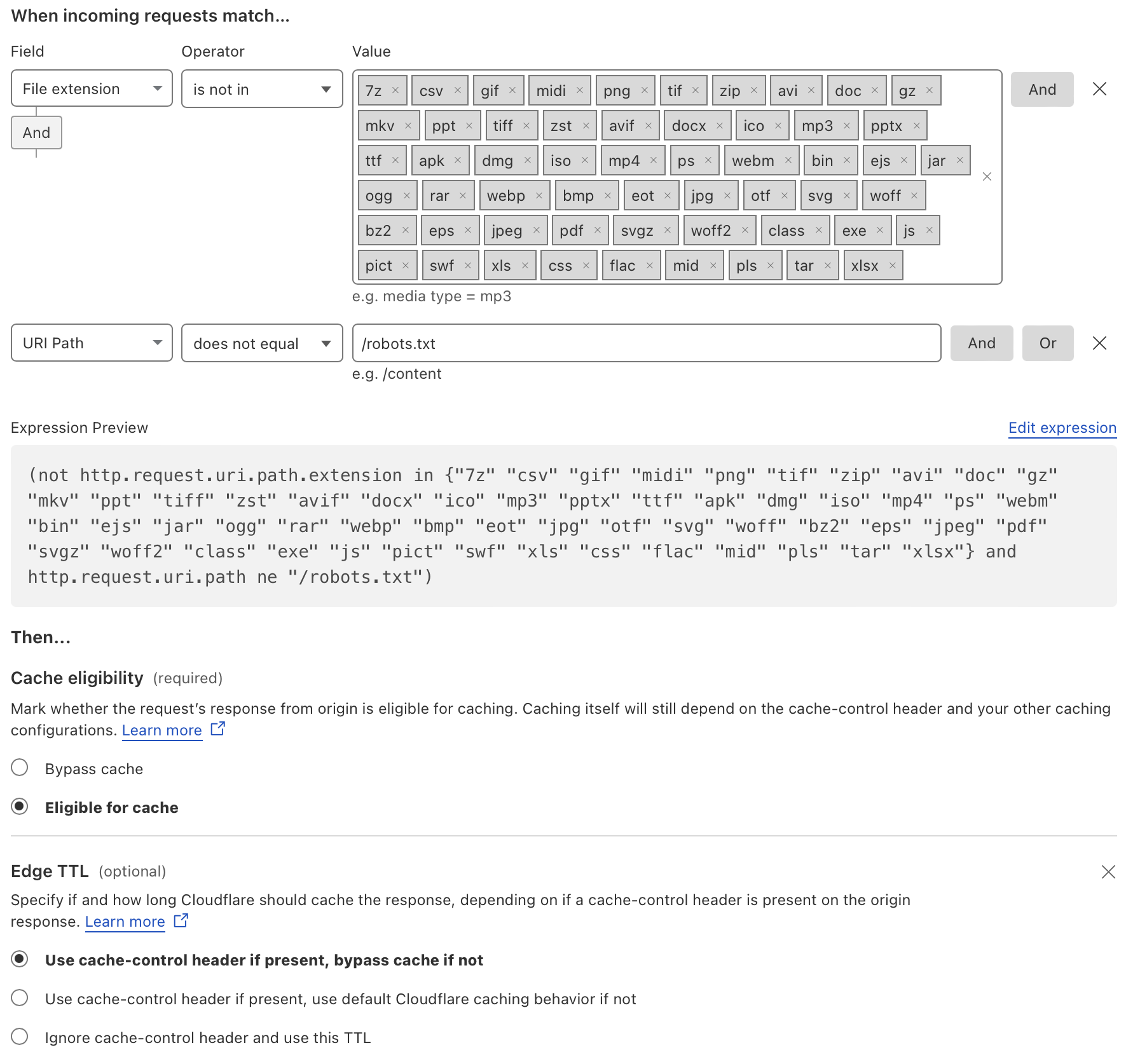
The expression used to match traffic not covered by the default caching policy is:
|
|
Conclusion
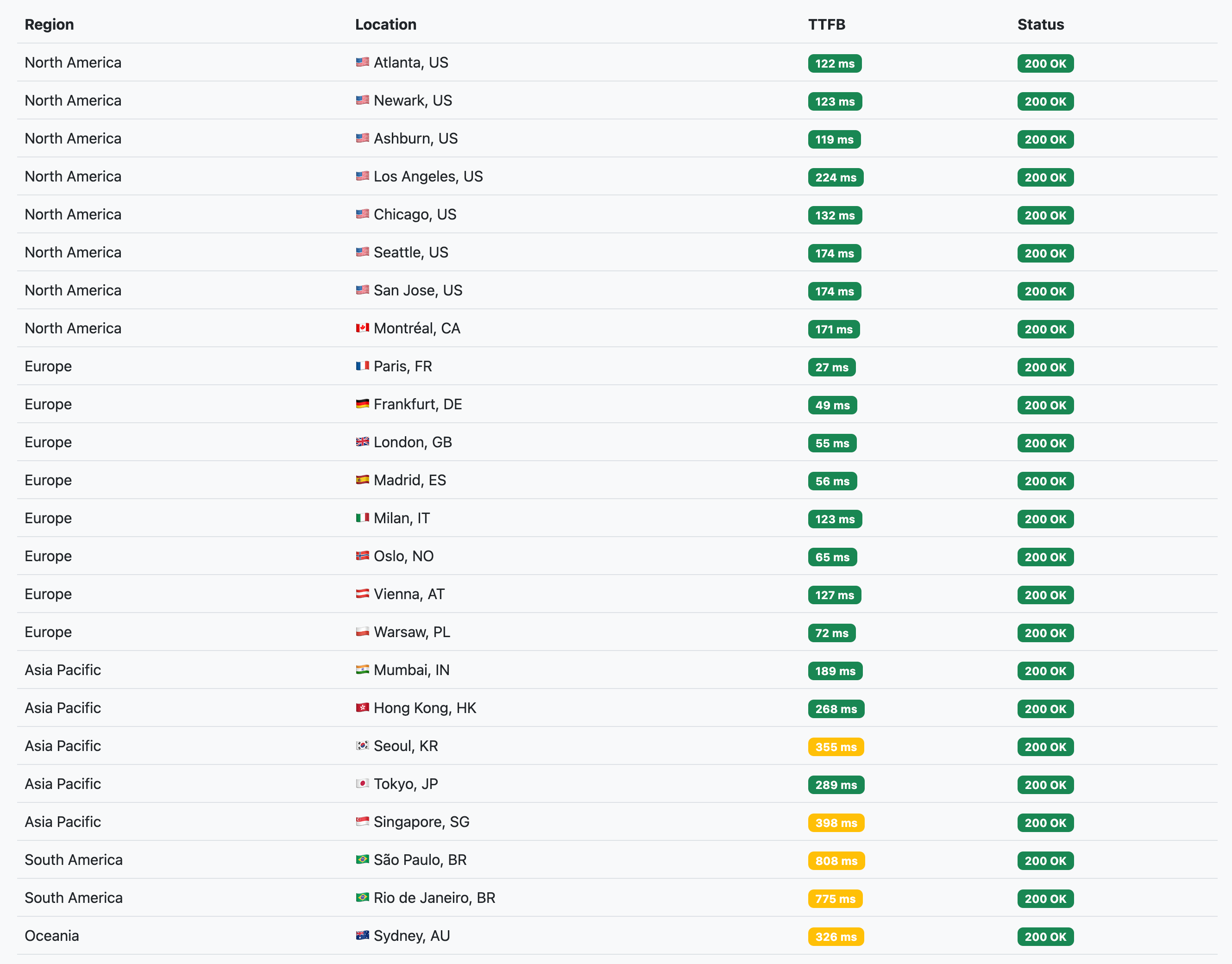
We did get a ~50% decrease in latency from the farther locations, which is pretty good for a single rule change. However, this only works for GET requests as other HTTP methods are never eligible for caching no matter what.
It would be awesome if Cloudflare made all requests, cacheable or not, go through Tiered Cache when it’s enabled. This behavior would be simpler in my opinion and more aligned with customer expectations, albeit rendering the more advanced Argo Smart Routing a bit less compelling.
-
By default, Cloudflare caches resources if they match a list of 56 file extensions (plus
/robots.txt) that are usually static assets (images, CSS, JS, etc.) and the origin response headers don’t forbid it. ↩︎ -
Cloudflare does monitor origin reachability and try to failover to a secondary path if the natural one goes down thanks to their Orpheus system. This is however resilience- and not performance-oriented. ↩︎
-
All
GETrequests, that is, as other methods are not cacheable at all and will always bypass the Cache phase. To make those faster, you’d have to use Argo Smart Routing (which is not so cheap) or build something similar yourself with Workers (which I’ve also done and will probably post about later). ↩︎ -
Or, more accurately, lukewarm potato-style, as the traffic between Cloudflare data centers does go traverse the Internet but through, one assumes, monitored and optimized paths. Anyway, the HTTP request is not merely tunneled but transmitted more efficiently instead, so we still win. ↩︎