Alors que je cherchais à évaluer les temps de latence HTTP dans le monde pour un petit projet dont je n’ai pas encore parlé, je me suis retrouvé un peu frustré par les limitations de l’outil en ligne que j’utilisais :
- Il était lent, visiblement parce qu’il collecte les résultats depuis toutes les localisations testées avant de commencer à les afficher au client (avec une longue animation simulant une arrivée séquentielle, qui plus est)
- Il fonctionnait mal : mes tests échouaient une fois sur trois
- Il était limité en nombre de tests par tranche de 12h, ce qui m’empêchait de faire tous les essais dont j’avais besoin
Ceux qui me connaissent le savent, il n’en fallait pas beaucoup plus pour que je refabrique l’outil à ma manière. Puisque le hasard fait bien les choses, j’étais justement en train de jouer avec les Cloudflare Workers, que je suivais de loin jusque là. Ce petit projet était l’objet d’étude idéal pour pousser plus loin l’exploration.
Quelques heures, un peu de JS et un soupçon de Bootstrap plus tard, voici TTFB Tester 🎉
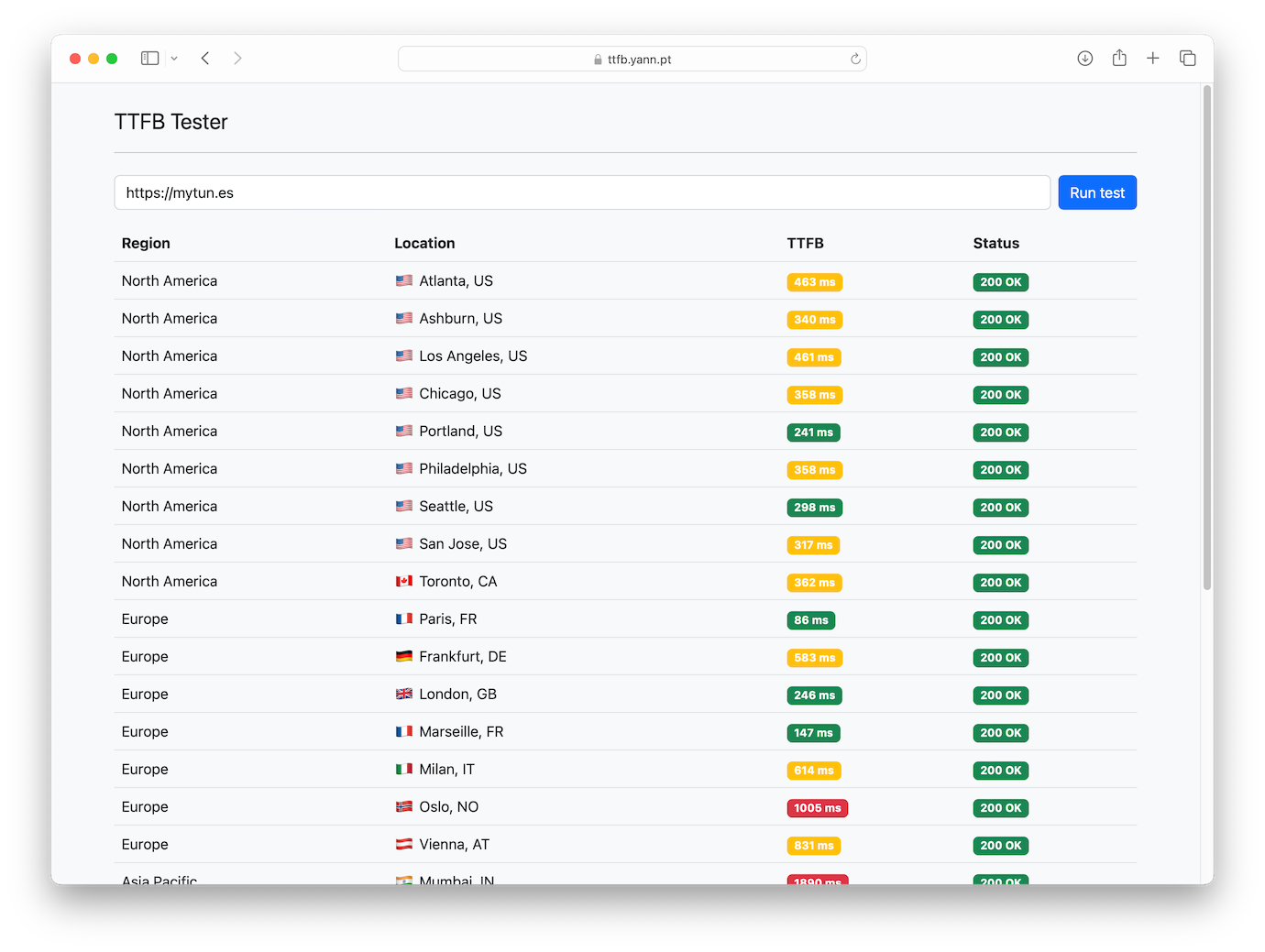 Certes, quand le cache du CDN est vide, ce n’est pas très joli. Un autre exemple :
Certes, quand le cache du CDN est vide, ce n’est pas très joli. Un autre exemple :
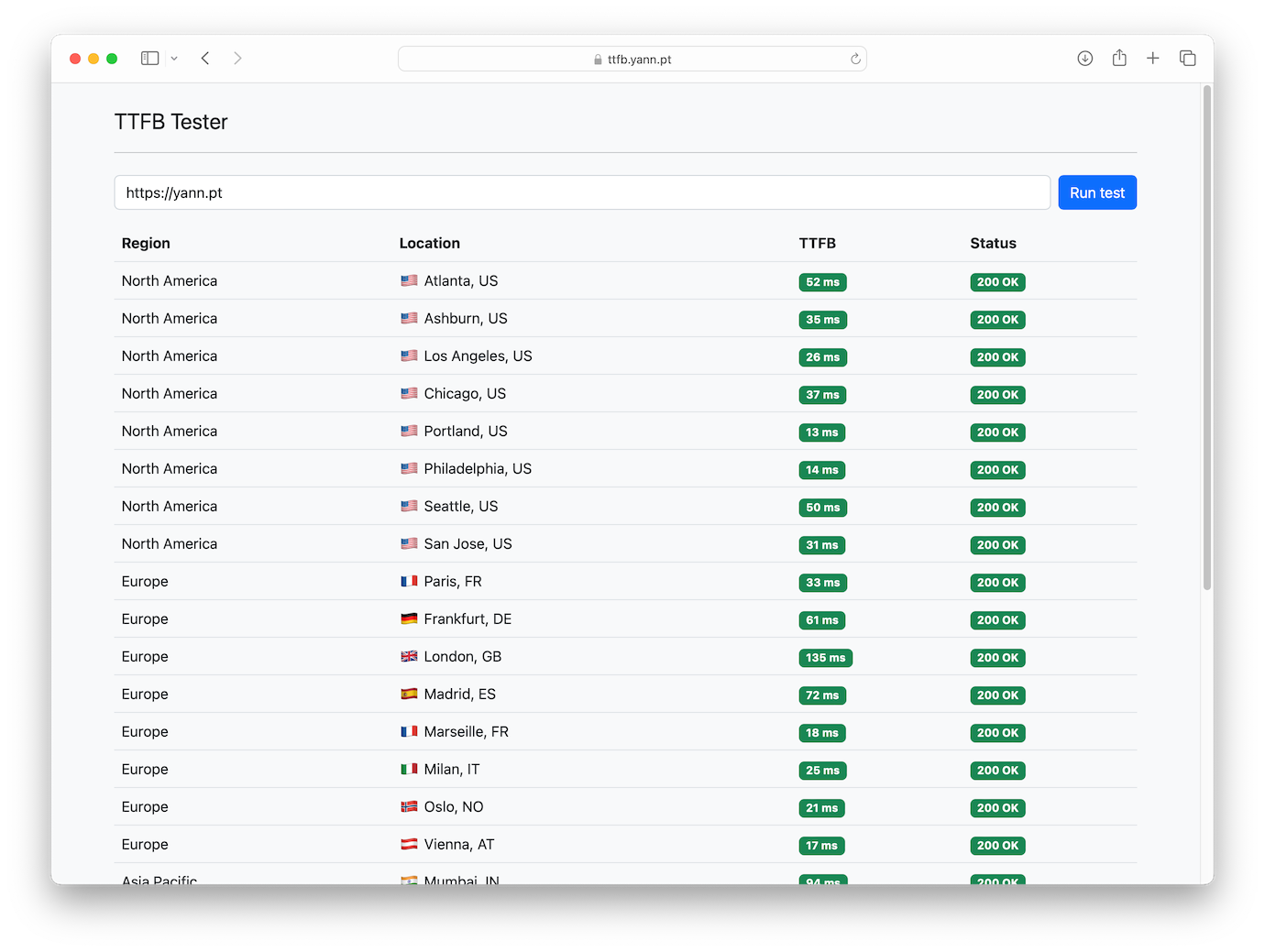
Côté technique, en attendant de m’étendre sur l’architecture, quelques solutions trouvées aux problèmes que j’avais avec l’outil tiers :
- Lenteur : Plutôt qu’une longue requête HTTP ne se terminant qu’une fois les résultats de toutes les localisations connus, chaque test est l’occasion d’ouvrir une connexion WebSocket avec un Cloudflare Worker qui joue le rôle d’orchestrateur. Ce dernier se charge de lancer les tests depuis les 28 datacenters en parallèle, puis envoie les résultats au client au travers dudit WebSocket au fur et à mesure de leur arrivée. Ainsi, les premiers chiffres arrivent souvent quasi instantanément, pendant que les autres localisations terminent leurs requêtes.
- Mauvais fonctionnement : Difficile de dire pourquoi certains tests échouaient sur l’autre outil. Peut-être des timeouts internes ou des problèmes de charge ? En tout cas, ici, chaque localisation est indépendante. Quand le test échoue pour l’une d’entre elles1, sa ligne disparaît discrètement du tableau de résultats sans pénaliser les autres. Cela ne vaut que pour les erreurs internes à l’outil : lorsque le test échoue à cause de la cible (erreurs 500, par exemple), la ligne reste pour l’indiquer.
- Quotas : Evidemment, le sujet est beaucoup plus simple quand c’est vous qui gérez les limites… Elles sont donc bien moins contraignantes ici, notamment parce que l’architecture serverless employée implique un coût quasi-nul au vu de mes prévisions d’usage.
Si une image vaut 1 000 mots, une expérience en vaut au moins le décuple… Pourquoi ne pas tester le testeur ? Ou même l’utiliser pour de vrais besoins, d’ailleurs : il est là pour ça.
-
C’est d’ailleurs (très) souvent le cas pour quelques localisations, et inhérent à la façon dont les tests sont orchestrés pour l’heure. Ces localisations sont tout de même incluses, parce que la nature de l’outil fait que tout résultat juste est bon à prendre : je recherchais ici l’exhaustivité avant la fiabilité. C’est ainsi qu’entre les deux captures d’écran ci-dessus, Toronto a laissé sa place à Madrid… ↩︎